Understanding Task Inputs
Task inputs are a crucial component in defining the structure and flow of data processing pipelines. They serve two primary functions:- Specifying the data requirements for each task
- Establishing the order of task execution
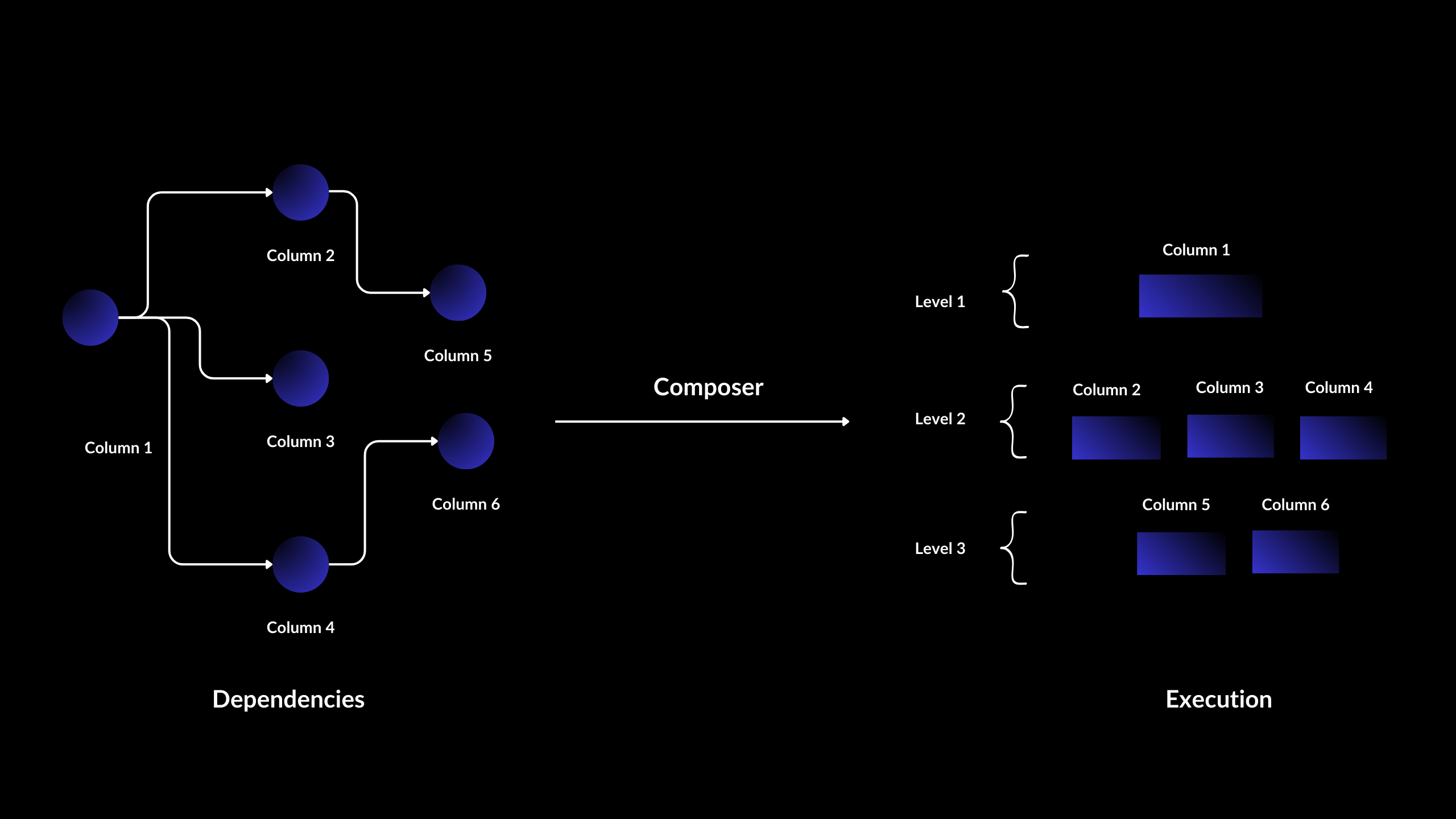
task_inputs field is used to define these relationships, effectively creating a Directed Acyclic Graph (DAG) of task dependencies. This DAG ensures that tasks are executed in the correct order, with each task receiving its required inputs only after they have been produced by preceding tasks.
Key Characteristics of the Task Input DAG:
- Directed: Relationships between tasks have a specific direction, from
inputtooutput. - Acyclic: The
graphdoes not contain cycles, preventing infinite loops in task execution. That’s fancy way to say “we make sure your data doesn’t end up chasing its own tail.” - Graph: Tasks and their dependencies form a
networkstructure.
invoice_parsingis the root node, with no dependencies.extract_customer_infoandextract_invoice_itemsboth depend onparsed_invoice.create_invoice_qnadepends on bothinvoice_itemsandcustomer_info.
- Tasks are executed in the correct order
- Each task has access to its required inputs
- Parallel execution is possible for independent tasks
Validation and Execution
The system performs validation on the task input definitions to ensure the DAG’s integrity:- Cyclic Dependency Check: Verifies that no cycles exist in the task dependencies.
- Existence Check: Confirms that all referenced inputs are defined.
- Type Consistency: Ensures that input and output data types are compatible.